Article
Jun 15, 2026
Voice AI Agent Mega Guide: Receptionists, IVR, Sales Calls, and Support
A guide for operators comparing voice AI, AI receptionists, IVR systems, call center automation, and human escalation.

Most teams do not need another AI demo. They need a narrower operating system for voice ai that removes a real constraint without creating new risk. This mega guide is written for service businesses, clinics, law firms, agencies, and sales teams that miss calls or spend too much staff time on repeat phone work. It answers the buying, build, governance, and measurement questions that usually get skipped until after the invoice is signed.
The short answer: a practical way to decide when voice AI is worth it, what it should say, what it should never say, and how to measure call outcomes. The useful version of voice ai starts with one workflow, one owner, one measurable baseline, and one review loop. It does not start with a platform list or a promise that AI will replace a team.
The keyword cluster behind this guide includes ai voice, voice ai, ai phone call, ai call center voice agent, ai voice agent, ai customer service agent, ai voice agents, ai customer service bot. Those terms show mixed intent: some readers want definitions, some want a vendor, and some want a cost model. This article is structured for all three intent layers so search engines, AI Overviews, and human buyers can extract a clear answer from each section.
The research base includes BLS customer service wage data, Twilio State of Customer Engagement, NIST AI Risk Management Framework, IBM guide to AI agents, Stanford 2026 AI Index. The Entropy internal context links are AI receptionist cost, AI voice agent vs IVR, AI receptionist for law firms, How much does an AI agent cost, AI agents vs automation, Contact Entropy. These links are not decorative citations. They support the two hardest parts of the decision: whether the market has moved enough to justify investment, and whether the implementation can be governed after launch.
Decision summary for voice ai
voice ai is worth pursuing when the workflow is frequent, measurable, rules-heavy at the edges, and expensive when delayed. It is not worth pursuing when the work is rare, the data is unreliable, or leadership cannot name the owner who will maintain it after launch.
A good first project has six traits: it happens every week, it has a visible trigger, it touches a business metric, it can be tested against historical examples, it has a human fallback, and it has a clear definition of done. If a project misses two of those traits, treat it as research rather than production.
Decision area | Strong signal | Weak signal |
|---|---|---|
Workflow fit | Repeated handoffs with known exceptions | One-off creative or political work |
Data readiness | Clean fields and stable source systems | Manual notes and duplicate records |
Risk | Human approval for edge cases | Unreviewed autonomous actions |
Economics | Baseline cost and outcome metric known | No current cost or owner |
Maintenance | Logs, alerts, and rollback planned | Agency keeps the only working knowledge |
What problem does this pillar solve?
The core problem is that voice AI fails when it is launched as a generic chatbot on the phone instead of a tightly scoped call workflow with fallback rules. That is why the first step is not tool selection. The first step is a constraint map: what starts the workflow, what data enters it, who touches it, where it stalls, what exceptions appear, and what business result should change.
For GEO and passage indexing, this matters because answer engines reward pages that give a direct answer and then show the operating conditions. A page that only says "voice ai helps businesses grow" is not citable. A page that explains triggers, owners, controls, costs, and tradeoffs can be cited in a specific answer.
Use this rule: if the work cannot be drawn as a before-and-after operating flow, it is not ready for a build. If it can be drawn, the next question is whether the AI step is deterministic, judgment-based, or advisory. Deterministic steps should stay automated without a model. Judgment steps need tests. Advisory steps need human review.
Operating model
The recommended operating model is voice AI handles narrow call intents, confirms data, books or routes, summarizes calls, and escalates uncertainty to people. This model keeps the system useful without making it reckless. The point is not to maximize autonomy. The point is to move the bottleneck while preserving accountability.
telephony provider should have a named owner, a success condition, and a fallback path.
speech-to-text should have a named owner, a success condition, and a fallback path.
LLM or dialog manager should have a named owner, a success condition, and a fallback path.
text-to-speech should have a named owner, a success condition, and a fallback path.
CRM should have a named owner, a success condition, and a fallback path.
calendar should have a named owner, a success condition, and a fallback path.
call summaries should have a named owner, a success condition, and a fallback path.
QA dashboard should have a named owner, a success condition, and a fallback path.
The stack should be designed around the smallest reliable loop. A loop has a trigger, a transformation, an action, a log, and a review. When teams skip the log, they lose trust. When they skip review, they lose control. When they skip a fallback, the first edge case becomes a production incident.
What is a voice AI agent?
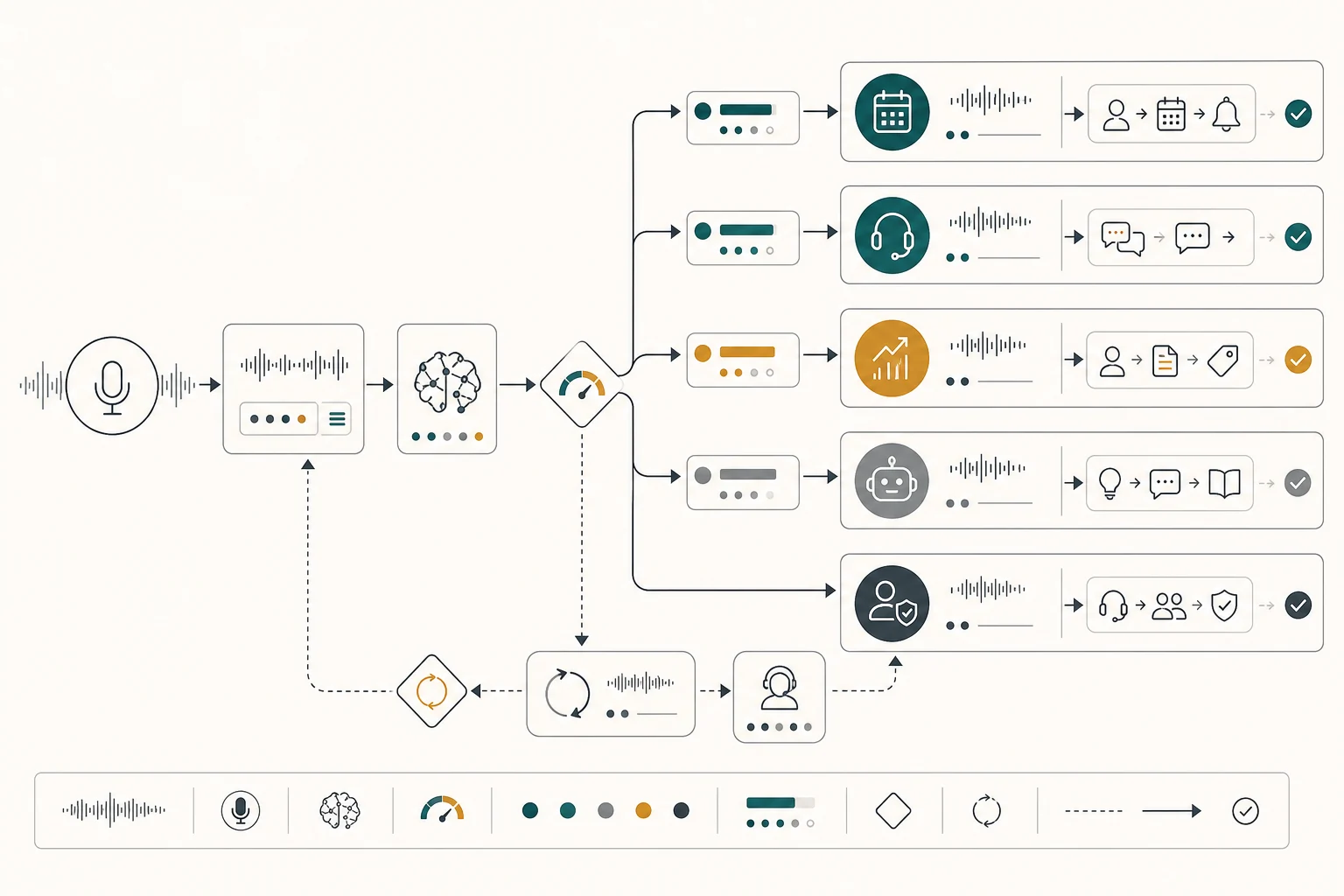
Start by mapping voice AI fails when it is launched as a generic chatbot on the phone instead of a tightly scoped call workflow with fallback rules. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
When is voice AI better than IVR?
Treat voice ai as a workflow redesign before it becomes a software build. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
Which calls should be automated first?
The safest answer is to narrow the first deployment until it can be tested end to end. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
How much does voice AI cost?
The business case is strongest when handoff accuracy is already visible. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
What should a voice agent know before a call?
Start by mapping voice AI fails when it is launched as a generic chatbot on the phone instead of a tightly scoped call workflow with fallback rules. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
How should escalation work?
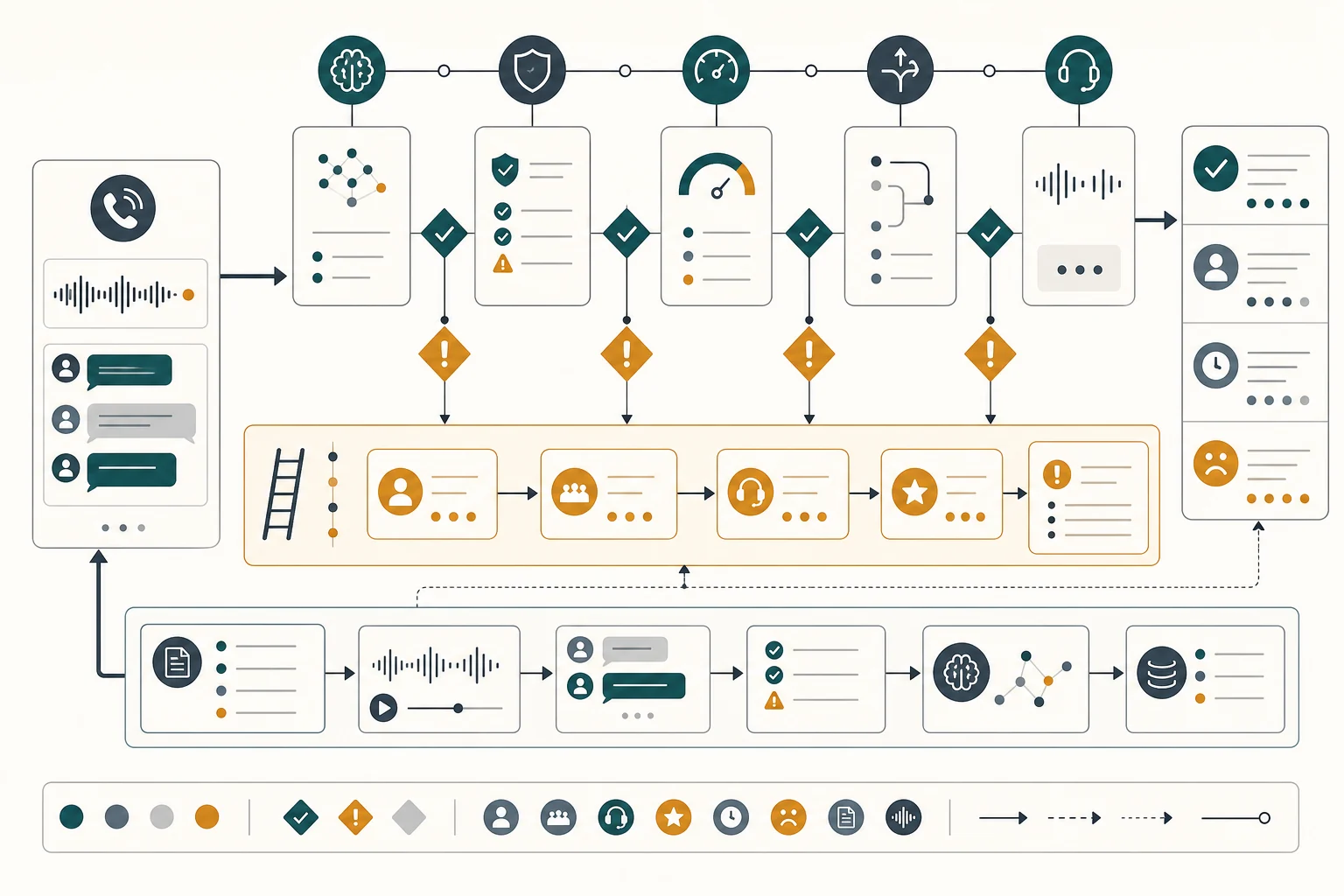
Treat voice ai as a workflow redesign before it becomes a software build. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
What should be logged after every call?
The safest answer is to narrow the first deployment until it can be tested end to end. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
How do you test latency and call quality?
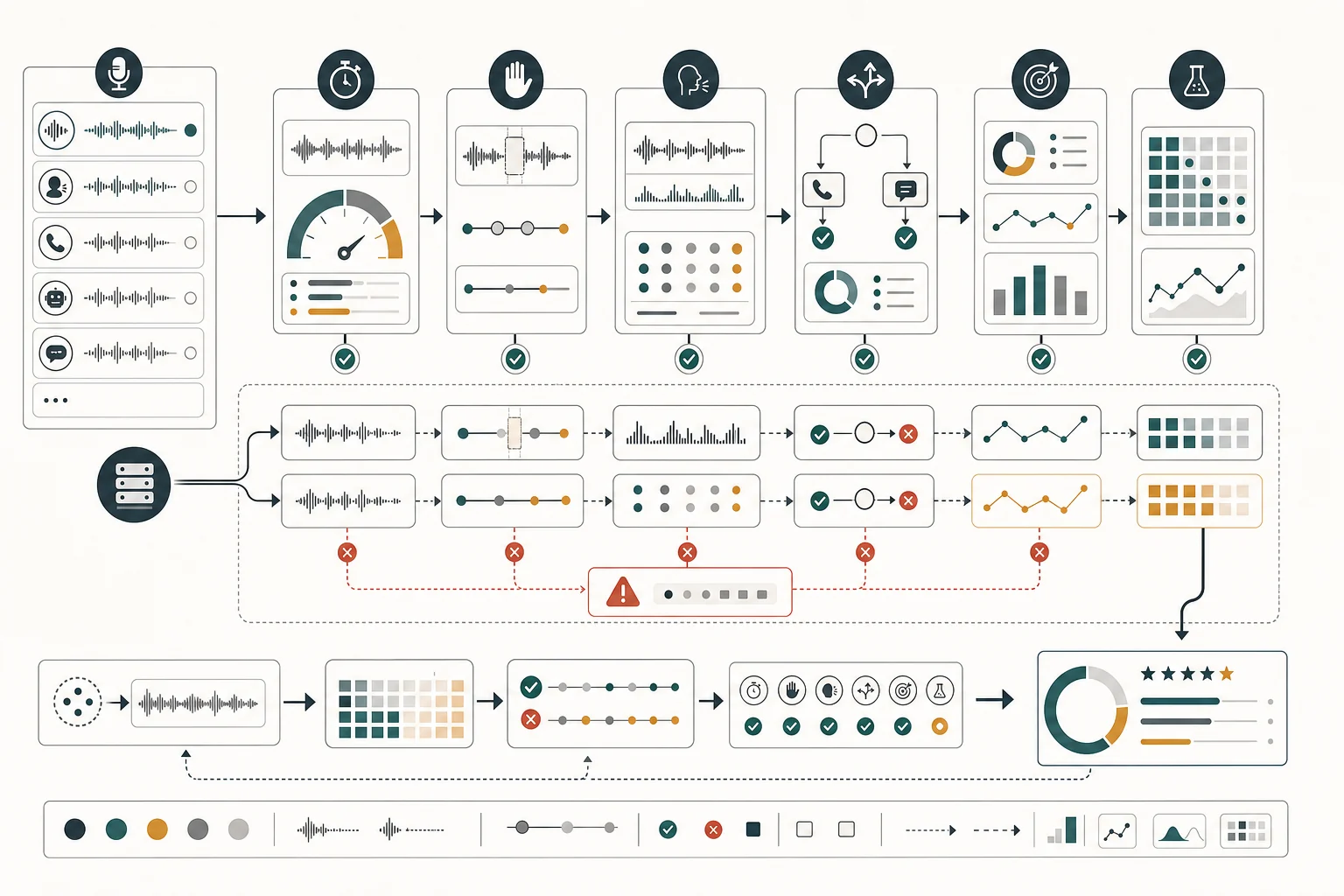
The business case is strongest when containment rate is already visible. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
What compliance and disclosure issues matter?
Start by mapping voice AI fails when it is launched as a generic chatbot on the phone instead of a tightly scoped call workflow with fallback rules. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
How do AI receptionists differ by industry?
Treat voice ai as a workflow redesign before it becomes a software build. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
What should a pilot include?
The safest answer is to narrow the first deployment until it can be tested end to end. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
When should you keep humans on the phone?
The business case is strongest when cost per resolved call is already visible. The answer depends on workflow frequency, data quality, buyer intent, risk tolerance, and whether the team can maintain the system after launch.
voice ai should be evaluated as an operating capability, not a software category. The strongest projects start with a narrow use case, then add adjacent steps only after the first loop has logs, exception handling, and a metric that matters. This is why pilots should be scoped around one job rather than one tool.
A practical review asks three questions. First, what happens if the system is wrong? Second, how quickly will a human notice? Third, what evidence proves the new workflow beats the old workflow? If those questions are uncomfortable, they are doing their job. They reveal whether the project is ready for production or still needs discovery.
Baseline: capture the current volume, cycle time, labor cost, and error rate before changing the workflow.
Control: define what the system can do alone, what requires approval, and what must stay human-owned.
Evidence: keep source records, prompts or rules, decisions, outputs, and reviewer notes in an audit trail.
Iteration: improve one failure mode per week instead of rebuilding the whole system after every complaint.
The mistake is trying to make the first version impressive. The better target is boring reliability. A boring system answers the same way, routes the same way, and fails in a visible way. Once the boring version works, the team can widen the use case with confidence.
Cost model and budget ranges
The budget should be tied to workflow complexity, not the label "voice ai." A narrow workflow with two integrations and one review queue can be a small project. A cross-functional system with permissions, reporting, approvals, and exception handling is a platform build.
Use three budget layers. The first layer is software: workflow tools, model calls, telephony, data enrichment, analytics, and hosting. The second layer is implementation: discovery, build, QA, documentation, and training. The third layer is maintenance: monitoring, prompt or rule updates, broken integrations, and quarterly business review.
If a vendor quotes only the build fee, ask for the operating cost. If a platform quotes only the subscription, ask who designs the workflow. If an internal team quotes only engineering time, add the cost of product ownership, QA, and support. The real comparison is total cost to reliable outcome.
90-day implementation plan
Days 1-15: Map the workflow, define the baseline, confirm data access, and remove any use case that lacks an owner.
Days 16-30: Build the narrowest working loop, run it against historical examples, and document failure modes.
Days 31-60: Pilot with live volume, keep human approval on risky actions, and review the first 100 outputs manually.
Days 61-90: Harden alerts, dashboards, and handoff documentation, then decide whether to expand or stop.
Measurement scorecard
The measurement layer should mix productivity, quality, risk, and revenue. One metric is not enough. A system can save hours while creating bad handoffs. It can increase replies while lowering fit. It can reduce cost while increasing risk. Track a balanced scorecard from the first pilot day.
answer rate: define the baseline, target, owner, and review cadence before the workflow goes live.
containment rate: define the baseline, target, owner, and review cadence before the workflow goes live.
booking rate: define the baseline, target, owner, and review cadence before the workflow goes live.
handoff accuracy: define the baseline, target, owner, and review cadence before the workflow goes live.
call abandonment: define the baseline, target, owner, and review cadence before the workflow goes live.
cost per resolved call: define the baseline, target, owner, and review cadence before the workflow goes live.
Common failure modes
The most expensive failures are predictable. They show up when teams treat AI as a shortcut around operations instead of a way to encode operations more clearly. The fix is usually not a better model. The fix is a clearer workflow, better examples, smaller permissions, and a human review point where judgment matters.
overpromising full replacement.
weak consent language.
no escalation path.
poor pronunciation testing.
unreviewed call summaries.
A strong vendor will name these risks before you do. A weak vendor will hide them behind a demo. During sales calls, ask what they refuse to automate, what they monitor after launch, and which failure modes caused their last redesign.
Vendor evaluation checklist
A useful vendor conversation should feel like an operations review, not a tool demo. The vendor should ask about data shape, owners, approval rights, current failure modes, and the business model. If the conversation stays at feature level, the delivery will probably stay at feature level too.
What workflow would you refuse to automate first and why?
What data fields do you need before scoping the build?
Where will human approval sit in the first version?
What happens when an integration fails?
How do you log decisions, prompts, source records, and outputs?
Which metric should improve within 30 days of launch?
What documentation will we own after handoff?
How will the system be maintained when tools change?
Source-backed notes for buyers
The outside research matters because the market is moving faster than most operating teams can absorb. Stanford 2026 AI Index shows how quickly AI adoption and capability are moving, while NIST AI Risk Management Framework gives teams a practical vocabulary for risk management. For implementation, Salesforce MuleSoft Connectivity Benchmark reinforces the connection between AI value and integration quality.
Do not read these sources as permission to automate everything. Read them as a warning that the teams who win will be the teams that connect AI to clean systems, governance, and measurable work. That is the difference between a useful operating layer and another subscription.
Related mega pillar guides
These companion guides connect adjacent buying decisions across AI automation, agent development, AI SEO, AI marketing, sales automation, voice AI, and n8n implementation. Use them as the cluster map when a project crosses more than one operating lane.
AI Automation Agency Mega Guide: Use Cases, Costs, and Vendor Fit
AI Agent Development Agency Buyer Guide: Build, Govern, and Scale
AI SEO and GEO Agency Mega Guide: Ranking, Citations, and Demand Capture
AI Marketing Agency USA Mega Guide: Ads, SEO, Email, and Automation
AI SDR and BDR Automation Mega Guide: Pipeline Without More Headcount
n8n AI Automation Mega Guide: Workflows, Agents, Pricing, and Governance
Related Entropy guides
AI voice agent vs IVR
FAQ
What is voice ai?
voice ai is the use of AI, automation, and connected systems to complete a specific business workflow with measurable output, review controls, and integration into the tools the team already uses.
How do I know if voice ai is worth it?
It is worth it when the workflow is frequent, expensive to delay, measurable, and stable enough to test. If the workflow happens rarely or depends mostly on executive judgment, start with advisory AI rather than automation.
What should the first project be?
The first project should be narrow enough to ship in weeks: lead routing, reporting, call intake, enrichment, follow-up, QA review, or a repeated handoff that already has a clear owner.
How much data access is required?
The system needs enough access to complete the job and no more. Start with read-only or scoped permissions, then add write access only after the workflow passes tests and approval rules are clear.
Should AI make final decisions?
AI can recommend, classify, draft, summarize, and route. Final decisions should stay human-owned when the action affects money, legal risk, customer trust, hiring, health, or irreversible account changes.
How long should implementation take?
A narrow pilot can usually be scoped, built, and tested in 30 to 60 days. A cross-functional production system with governance, permissions, reporting, and training can take 90 days or more.
What should be documented?
Document triggers, data fields, prompt or rule logic, tool permissions, known failure modes, escalation paths, owner names, dashboards, and the procedure for pausing or rolling back the workflow.
What KPIs matter most?
Use a balanced scorecard: speed, quality, cost, risk, and business outcome. A system that saves time but creates bad handoffs is not a win.
Can an internal team build this instead of hiring an agency?
Yes, if the team has workflow ownership, integration skill, QA capacity, and time to maintain the system. Hire an agency when speed, cross-tool experience, or governance design matters more than learning everything internally.
What is the biggest mistake buyers make?
The biggest mistake is buying a tool before defining the workflow. Tool selection should come after baseline measurement, owner assignment, data review, and risk mapping.
Bottom line
voice ai works when it is attached to a real bottleneck, not a vague transformation goal. Start with one workflow, prove the baseline moved, document the controls, and only then expand the system. That is slower than buying a tool, but it is much faster than cleaning up an expensive deployment that nobody trusts.